日本の排他的経済水域の地図データ
仕事で日本の排他的経済水域の地図データを探していたのだが、日本の国土地理院の数値データ
(国土数値情報ダウンロードサービス)などは見当たらなかった。
日本の排他的経済水域は、海上保安庁のウェブサイトではこういう形になっている。

しかし、実際はいくつかの係争中水域や共同開発区域が存在する。
Rには、MazamaSpatialUtilというパッケージがあり、EEZの地図データが含まれている。
それによると、日本のEEZと係争中のエリアを区分けすると次のようになる。

# library pacman::p_load( tidyverse, sf, rnaturalearth, patchwork ) # Use function `%!in%` <- Negate(`%in%`) # Japan land japan_sf <- ne_countries(country = c('japan','russia','south korea','north korea','china','taiwan','united states of america'),scale="large", returnclass = "sf") %>% st_transform(crs=4326) # EEZ from MazamaSpatialUtils eez_sf=MazamaSpatialUtils::SimpleCountriesEEZ %>% st_as_sf() %>% st_transform(crs=4326) %>% filter(countryName %in% c("Japan","South Korea","China","Taiwan","Russia")) %>% filter(polygonID %!in% c(22,100,189,33)) # remove mainland China # test plot of EEZ ggplot(data=eez_sf) + geom_sf(fill="lightblue") + geom_sf(data=japan_sf) + #geom_sf_label(aes(label=polygonID)) + theme_bw() + lims(x=c(120,160),y=c(15,48))
見比べてみると、韓国との暫定水域について、日本の概念図では竹島を日本側に含むラインがあるが、このデータでは存在しない事がわかる。
すなわち、「暫定水域」を定義するラインが存在しない。
EEZのデータは、他にMarine Regionsというウェブサイトで取得することができる。
このウェブサイトでは、EEZのデータについてバージョンが3つ存在する。
Version 1は2012年, Version 2は2014年, Version 3は2020年にリリースされている。
このうち、Version 2と3をダウンロードし、MazamaSpatialUtilのデータと比較してみた。

すると、MazamaSpatialUtilのデータと、Version 3のデータは一致しているが、Version 2とは異なることが示された。
以下が描画に使用したコードである。
eez_sf_v2 = st_read("EEZ_land_union_v2_201410/EEZ_land_v2_201410.shp") %>% filter(str_detect(Country,"Japan")|str_detect(Country,"South Korea")|str_detect(Country,"Russia")|str_detect(Country,"China")) %>% st_transform(4326) # Marine Regions ver 3 eez_sf_v3 = st_read("EEZ_land_union_v3_202003/EEZ_Land_v3_202030.shp") %>% filter(SOVEREIGN1 %in% c("Japan","South Korea","Russia","China")|SOVEREIGN2 %in% c("Japan","South Korea","Russia","China")|SOVEREIGN3 %in% c("Japan","South Korea","Russia","China")) %>% st_transform(4326) # plot of EEZ: version 2 + version 3 comparison around Takeshima plot_v2_v3_nationwide = ggplot() + geom_sf(data=eez_sf_v2,fill="transparent",col="blue") + geom_sf(data=eez_sf_v3,fill="transparent",col="red") + geom_sf(data=eez_sf,fill="transparent",col="green",linetype=2) + geom_sf(data=japan_sf) + annotate(geom = "text",label="Marine Regions version 2", x=142,y=20,col="blue",hjust=0) + annotate(geom = "text",label="Marine Regions version 3", x=142,y=19,col="red",hjust=0) + annotate(geom = "text",label="MazamaSpatialUtils", x=142,y=18,col="green",hjust=0) + labs(title="Marine Regions EEZ data: version 2 & 3") + lims(x=c(120,158),y=c(15,48)) + theme_minimal() plot_v2_v3_nationwide
日本海を拡大すると、次のようになる。

# plot of EEZ: version 2 + version 3 comparison around Takeshima island plot_v2_v3 = ggplot() + geom_sf(data=eez_sf_v2,fill="transparent",col="blue") + geom_sf(data=eez_sf_v3,fill="transparent",col="red") + geom_sf(data=eez_sf,fill="transparent",col="green",linetype=2) + geom_sf(data=japan_sf) + annotate(geom = "text",label="Marine Regions version 2", x=137,y=33,col="blue",hjust=0) + annotate(geom = "text",label="Marine Regions version 3", x=137,y=32.5,col="red",hjust=0) + annotate(geom = "text",label="MazamaSpatialUtils", x=137,y=32,col="green",hjust=0) + labs(title="Marine Regions EEZ data: version 2 & 3") + lims(x=c(125,145),y=c(32,42)) + theme_minimal() plot_v2_v3
Version 2では、韓国との暫定水域とみられるものがデータとして記録されている。
そのため、冒頭の「日本の領海等概念図」に近い地図データを得るためにはMarine RegionsのVersion 2を利用すると可能となる。

# 日本が入るポリゴンの抽出
eez_sf1= st_read("data/raw/EEZ_land_union_v2_201410/EEZ_land_v2_201410.shp") %>%
filter(str_detect(Country,"Japan")) %>%
st_transform(4326)
# ポリゴンを結合
eez_sf2 = eez_sf1%>%
st_union()
# test plot of EEZ (polygon separated)
ggplot() +
geom_sf(data=eez_sf1,fill="lightblue") +
geom_sf(data=japan_sf) +
geom_sf_label(data=eez_sf1,aes(label=OBJECTID)) +
lims(x=c(120,157),y=c(18,48)) +
theme_minimal()
# test plot of EEZ (combined)
ggplot() +
geom_sf(data=eez_sf2,fill="lightblue") +
geom_sf(data=japan_sf) +
lims(x=c(120,157),y=c(18,48)) +
theme_minimal()
なぜVersion 2からVersion 3への変更について、境界線がこのようになっているかはわからない。
【R】n番目に大きい値をdplyr::summariseする。
問題
グループごとに平均や最大値などを計算するのに便利なdplyr::summariseですが、たとえば2番めに大きい値を計算したい、というときはどうすればいいか?
解決策
自分で簡単な関数を書く。
max2 <- function(x) { u <- unique(x) sort(u, decreasing = TRUE)[2L] }
解説
準備
標準装備mtcarsのデータを例に使います。
# パッケージ library(tidyverse) # dplyr含む # データロード data(mtcars)
ステップ1:最大とか
オートマ/マニュアル別に一番いい燃費はいくらか?
> mtcars %>% group_by(am) %>% summarise(mpg_max = max(mpg), mpg_mean = mean(mpg)) # A tibble: 2 × 3 am mpg_max mpg_mean <dbl> <dbl> <dbl> 1 0 24.4 17.1 2 1 33.9 24.4
最大だとオートマは24.4、マニュアルは33.9、単位はそれぞれガロンあたりのマイルです。
ステップ2:関数を書く
dplyrにはslice_max(旧top_n)という関数があるのですが、これは大きい方からn個を引っ張ってくる関数です。
n番目だけ(たとえば2番めだけ)を引っ張ってきたいならいっそ関数書いてしまったほうが早そう。
max2 <- function(x) { u <- unique(x) sort(u, decreasing = TRUE)[2L] }
> mtcars %>% group_by(am) %>% summarise(mpg_max = max(mpg), mpg_mean = mean(mpg), mpg_max2 = max2(mpg)) # A tibble: 2 × 4 am mpg_max mpg_mean mpg_max2 <dbl> <dbl> <dbl> <dbl> 1 0 24.4 17.1 22.8 2 1 33.9 24.4 32.4
2Lの数字を変えれば、n番目の数字に対応します。
【R】とりあえず簡単にggpplot2で2軸目を書きたい時はsec.axis
数ヶ月に一回ググってる気がするので自分用にメモ。
問題
とりあえずggplot2でエクセル的な2軸プロット(左右に別のY軸があってグラフが重なってるやつ)を書きたい。
ググっても丁寧なブログはたくさん見つかるのだが、とりあえずどれやればいいの!となる。
ggplot2以外に追加的にパッケージとかも使いたくない。
解決策
sec.axisをscale_y_continuous()で使う。
# 適当な例 ggplot(data, aes(x=x,y=y, col=group)) + geom_line()+ scale_y_continuous(sec.axis=sec_axis(~.*10, name="y2")) #ココ!
解説
準備
標準装備airqualityのデータを例に使います。
# パッケージ library(tidyverse) # ggplot2含む # データロード data(airquality) # 時系列データにするためにDate変数を作成 airquality = airquality %>% # 元データに月と日はあり(MonthとDay)。年は適当に今年になる。 mutate(date = as.Date(paste(Month,Day,sep="-"), format="%m-%d"))
ステップ1:とりあえず描画
ワイドデータ(異なる変数がそれぞれの列で記録されているデータ)をそのまま描画する場合です。
ロングデータ(変数の値が一つの列に記録され、もう一つの列に変数名やカテゴリが記録されてるようなデータ)は後述。
まずとりあえずデータをそのまま描画すると以下のようになる。
ggplot(data=airquality, aes(x=date)) + geom_line(aes(y=Wind,col="Wind"))+ geom_line(aes(y=Temp,col="Temp"))

なんかちょっと離れてるので重ねたい、みたいなときありますよね。
ステップ2:スケールする
一方の変数に係数をかけたり足し引きしたりすることでスケールする。
このスケールは、使うデータによるので、ここは数字みながら試行錯誤する必要ありです。
今回はシンプルに2つ目の変数である温度(temp)の数値が高いのでいい感じの数を引いてます。
# トライ2 スケールする
ggplot(data=airquality,
aes(x=date)) +
geom_line(aes(y=Wind,col="Wind"))+
geom_line(aes(y=Temp-70,col="Temp"))

ステップ3:2軸目を足す
ここが一番の肝。
scale_y_continousの中でsec.axisという引数を使う。
このときに、sec_axisという関数で、数値をスケールすることができる。
上で70引いているので、ここでは70を足すことで本来の数値を表示できる。
# トライ3 2軸目を足す ggplot(data=airquality, aes(x=date)) + geom_line(aes(y=Wind,col="Wind"))+ geom_line(aes(y=Temp-70,col="Temp"))+ scale_y_continuous(sec.axis = sec_axis(~.+70)) # 2軸目のY軸

ステップ4:2軸目のラベルを足す
2軸目がなんなのか表示する。
nameという引数で表示できるが、sec_axis関数の中でつかうこと!
カッコを見間違えてsec_axisの外、scale_y_continuousの引数としてnameを使うと、エラーが返されずに第1軸のラベルとして認識されてしまう。
2軸だと単位が異なる事が多いので、軸ラベルに単位を明示すると丁寧ですよね。
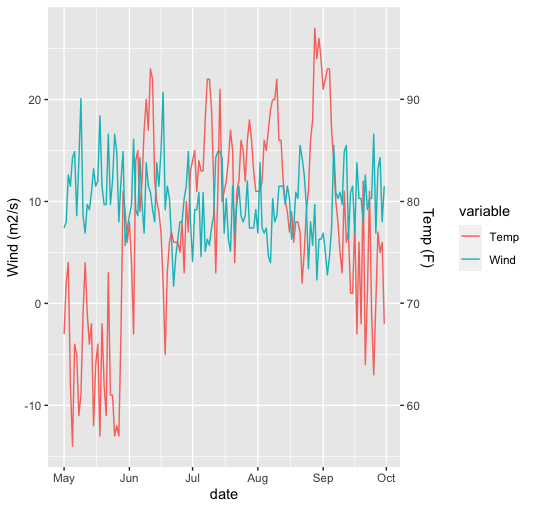
ggplot(data=airquality, aes(x=date)) + geom_line(aes(y=Wind,col="Wind"))+ geom_line(aes(y=Temp-70,col="Temp"))+ scale_y_continuous(sec.axis = sec_axis(~.+70, name="Temp (F)"), name="Wind (m2/s)" )

なんでこんな気温高いんだと思ったら華氏(F)だからでした。
さらに細かくカスタマイズしたりスケールを設定するには「ggplot 2軸」とかで検索するとたくさんひっかかるのですが、とりあえず2軸!じゃあsec.axis!というのを覚えるために書きました。
おまけ:ロングデータ
ggplotだとロングデータ使って、color引数とかでカテゴリを色分けすることとか多いんですが、その場合はデータに予めスケールをかけとくほうがいいかもです。
以下はロングデータとワイドデータの違い。今回はOzoneとSolar.Rは無視してます。
#ロングデータに変換 airquality_long = airquality %>% pivot_longer(cols=c(Temp,Wind),names_to = "variable",values_to = "value") # ロングデータ > head(airquality_long) # A tibble: 6 × 7 Ozone Solar.R Month Day date variable value <int> <int> <int> <int> <date> <chr> <dbl> 1 41 190 5 1 2022-05-01 Temp 67 2 41 190 5 1 2022-05-01 Wind 7.4 3 36 118 5 2 2022-05-02 Temp 72 4 36 118 5 2 2022-05-02 Wind 8 5 12 149 5 3 2022-05-03 Temp 74 6 12 149 5 3 2022-05-03 Wind 12.6 #ワイドデータ > head(airquality) Ozone Solar.R Wind Temp Month Day date 1 41 190 7.4 67 5 1 2022-05-01 2 36 118 8.0 72 5 2 2022-05-02 3 12 149 12.6 74 5 3 2022-05-03 4 18 313 11.5 62 5 4 2022-05-04 5 NA NA 14.3 56 5 5 2022-05-05 6 28 NA 14.9 66 5 6 2022-05-06
スケールした新しい変数を作成
airquality_long = airquality_long %>% # もしvariableがTempなら70引く mutate(value2 = ifelse(variable=="Temp",value-70,value))
通常のggplot2の文法で書く。このときvalueではなくvalue2をy変数にセットする。
2軸の書き方は上と全く同じです。
ggplot(data=airquality_long, aes(x=date,y=value2,col=variable)) + geom_line()+ scale_y_continuous(sec.axis = sec_axis(~.+70, name="Temp (F)"), name="Wind (m2/s)" )
【R】geom_sfで地図描こうとしたらst_cast.POINTというエラーが出た。
またしても備忘録
問題
ggplotを使ってsfオブジェクトを描画しようとすると以下のエラーが出た。
Error in st_cast.POINT(x[[1]], to, ...) : cannot create MULTILINESTRING from POINT
解決策
球形幾何のパッケージであるs2が有効になっていると起こる問題であるらしい。
s2を無効にしてやればとりあえず問題は解決する。
sf_use_s2(FALSE)
")
【R】Macでextrafont::font_import()を使うとエラーが出る話
備忘録。あとできちんと清書するかも。
問題
extrafontパッケージを使ってフォントをRにインストールしようとしたら引っかかったので調べた結果。
extrafont::font_import()を使うとNo FontName. Skippingと出てインストールされないエラーが出る。
解決策
解決策 1
R4.1.0にしてると出る問題らしく、Rttf2pt1というパッケージをダウングレードすると直るらしい。
library(remotes) remotes::install_version("Rttf2pt1", version = "1.3.8")
解決策 2
それでも治らなかったのだが、まずextrafontパッケージをインストールし直してから、もう一度ダウングレードをやると直った。
解決策 3
Macの場合、font bookというアプリでコンピューターにインストールされてるフォントを管理していて、それをRにfont_import()でインストールするわけだが、
アクセス権の問題で、自分のユーザーには使いたいフォントがインストールされているが、コンピュータ全体には反映されてなかったりする。
ので、font bookを開き(たとえばSpotlight検索でfont book)、環境設定からデフォルトのインストール場所をコンピュータに変えてから、使いたいフォントをコンピュータにインストールすると解決するかも。
Adding Fonts to R using extrafont or showtext libraries (on Mac via FontBook) - Stack Overflow
【R】差の差法でイベントスタディやるときのコード
Rのfixestパッケージが先月末にアップデートされたようです。
このブログ投稿はこのバージョンの話ではないですが、3つ以上の固定効果を使うと、固定効果の推定がおかしくなるバグを直したらしいのでアプデ推奨のようです。
⚠ Hot Fix ⚠
— Laurent Bergé (@lrberge) April 1, 2022
Concerns #Rstats {fixest} users working in int. trade
When using 3+ fixed-effects, the value of the FE coefficients extracted with {fixef()} could be erroneous.
Pls update to 0.10.4 to fix this (ps: you need to build from source)https://t.co/mmEzLLlVEg
1/2
さて、本題です。
差の差法(Difference in Differences, DID)のイベントスタディ*1をやろうと思って推定しても、図書くのめんどいなということがあったのですが、fixestの関数使えば簡単にできるようになっていたのでメモ。*2
準備
fixestパッケージに入っているbase_didというデータセットで実演します。
# パッケージロード library(fixest) # データサマリー > skimr::skim(base_did) ── Data Summary ──────────────────────── Values Name base_did Number of rows 1080 Number of columns 6 _______________________ Column type frequency: numeric 6 ________________________ Group variables None ── Variable type: numeric ───────────────────────────────────────────────────────────────────────────────────────────────────────────── skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100 hist 1 y 0 1 2.02 5.71 -15.1 -1.87 1.74 5.78 21.5 ▁▆▇▃▁ 2 x1 0 1 0.0353 2.98 -10.6 -2.04 0.0941 2.08 9.75 ▁▃▇▅▁ 3 id 0 1 54.5 31.2 1 27.8 54.5 81.2 108 ▇▇▇▇▇ 4 period 0 1 5.5 2.87 1 3 5.5 8 10 ▇▇▇▇▇ 5 post 0 1 0.5 0.500 0 0 0.5 1 1 ▇▁▁▁▇ 6 treat 0 1 0.509 0.500 0 0 1 1 1 ▇▁▁▁▇ # timing of policy: 政策の施行はピリオド6から table(base_did$period, base_did$post) # treated individuals: 1-55 政策が施行されるグループには1番から55番の個人が入る。全部で108番までいる。 table(base_did$id, base_did$treat)
2 x 2の差の差法
一番基本的な差の差法の推定である、施行前後ダミー・処置ダミー・政策ダミー(2つのダミーの相互作用)による2x2の推定は以下の通り
# 2 x 2 model1 <- feols(y ~ post*treat, data = base_did)
> model1 OLS estimation, Dep. Var.: y Observations: 1,080 Standard-errors: IID Estimate Std. Error t value Pr(>|t|) (Intercept) 0.322801 0.317345 1.017194 3.0929e-01 post 0.713468 0.448793 1.589747 1.1219e-01 treat 0.142340 0.444695 0.320084 7.4897e-01 post:treat 4.993390 0.628893 7.939967 5.0601e-15 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 RMSE: 5.15642 Adj. R2: 0.180566
固定効果モデル
2-way fixed effect modelは二元配置固定効果推定法というのかな?
時間と個人の固定効果をそれぞれ含めたモデルは以下の通り。
# 2 way fixed effects model2 <- feols(y ~ post:treat | id + period, data = base_did) # feols(y ~ post:treat, data = base_did, fixef = c("id","period")) でもOK
結果 > model2 OLS estimation, Dep. Var.: y Observations: 1,080 Fixed-effects: id: 108, period: 10 Standard-errors: Clustered (id) Estimate Std. Error t value Pr(>|t|) post:treat 4.99339 0.521434 9.57627 4.6502e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 RMSE: 4.74941 Adj. R2: 0.222439 Within R2: 0.064601
イベントスタディ
事前トレンドの仮定を評価するために、イベントスタディモデルで推定したい場合は処置ダミーと時間ピリオドの相互作用項を使います。
i()関数で簡単にできる上に、ベースとなる時間ピリオドの指定もできます。
この場合は、時間ピリオドの6以降が政策施行の期間なので、直前の5をベースにしています。
# event study model3 <- feols(y ~ i(period,treat, ref = 5) | id+period, data = base_did)
> model3 OLS estimation, Dep. Var.: y Observations: 1,080 Fixed-effects: id: 108, period: 10 Standard-errors: Clustered (id) Estimate Std. Error t value Pr(>|t|) period::1:treat -2.015417 1.34235 -1.501414 1.3619e-01 period::2:treat -1.664474 1.38858 -1.198689 2.3330e-01 period::3:treat 0.504127 1.32338 0.380939 7.0400e-01 period::4:treat -0.884617 1.41588 -0.624784 5.3344e-01 period::6:treat 1.159133 1.22689 0.944775 3.4690e-01 period::7:treat 4.334751 1.30818 3.313584 1.2575e-03 ** period::8:treat 3.825722 1.51448 2.526102 1.2998e-02 * period::9:treat 4.640141 1.29328 3.587874 5.0439e-04 *** period::10:treat 6.946824 1.42559 4.872933 3.8321e-06 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 RMSE: 4.69194 Adj. R2: 0.234782 Within R2: 0.087104
いい感じの結果が出ています(作られたデータなんで当たり前ですが)。
この結果を図にするときに、わざわざ係数と標準誤差を抜き出して、データフレームにして加工してからggplotで描画、なんてしていましたが、
少なくともざっと結果を見る分にはその必要がありません!
係数をプロットする関数を用意してくれています。
係数プロット
coefplot(model3)

coefplot()関数を使うと、推定された係数を標準誤差による95%信頼区間のエラーバー付きで表示してくれますが、もし他に説明変数を入れていると、それも表示してしまいます。引数dropなどで編集はできますが、次のiplot()関数を使うと、イベントスタディとしてすごく見やすい図を作ってくれます。
iplot(model3)

ベースとなる時間ピリオドに縦線を勝手に引いてくれるので、政策前後がわかりやすくなっています。i()関数で推定した係数のみを表示するので、変数の選択などの引数も不要です。
fixestまじですごいな…以上メモでした。
*1:event study 9 Difference-in-Differences | Causal Inference
*2:この関数自体は昨年6月頃の0.9.0のアップデートで実装されてたようです。
【読書】ウクライナ危機の今、「100年予測」を読み返す。
ロシアがウクライナに侵攻して早一ヶ月。
当初予測されていたよりウクライナが踏ん張っているというニュースが届くも、空爆や砲撃でボロボロになったウクライナの街や傷ついた一般市民が報道される姿は見ていて心が痛い。
戦争には反対だし、どんな理由があっても許されることではない。しかし、何がここまでの状態を引き起こしたのかという背景を理解することは、これから起こりうることに準備することにも資する。
今回のウクライナ侵攻を見て、思い出したのが数年前に読んだ「100年予測」である。

100年予測 ジョージフリードマン著 櫻井祐子訳
本書は、ハンガリー生まれのアメリカの地政学者であるジョージ・フリードマンが書いた文字通り100年先の世界を予測する本である。
原書は2009年に、翻訳は2010年に出版され、その後クリミア危機を予測した!と話題になって文庫版が2014年に発売された。
最終的には日本がアメリカに宇宙戦争を仕掛ける、という「ねーよwww」という展開もあるのですが、どういうロジックでそういう結論が導き出されるか?という部分は興味深いです。
とくに序盤のロシアや中国の動きは、一読に値すると思う。
以下は、私が2015年に読んだときの読書記録ですが、改めてシェアします。
情報機関の創設者が21世紀に起こる政治・経済の危機を地政学に基づいて”予測”する。
100年先を予測するにおいて、この本の結論、つまり予測結果そのものだけを見ると馬鹿馬鹿しいというか、ありえない、という印象を抱く。しかし、それを見越した導入部分が面白い。1900年の夏にいると想像する。世界の首都はロンドンで、ヨーロッパ諸国が東半球を支配し、世界のほとんどが間接的には、ヨーロッパの支配下にあった。その20年後、ヨーロッパは大戦によって引き裂かれ、オーストリア=ハンガリー、ロシア、ドイツ、オスマントルコといった帝国は消え去った。アメリカや日本といったヨーロッパ外の国が台頭し、不利な講和条約をおしつけられたドイツは立ち直れないと思われていた。その20年後、1940年には、再びドイツが台頭し、ヨーロッパを支配、海峡を隔てているイギリスのみが対抗しうる存在であると思われ、ドイツが帝国を継承すると思われた。1960年、ドイツは第二次大戦で敗北、アメリカとソ連によって占領されていた。アメリカが世界のリーダーとして躍り出た。核装備による冷戦が始まり、共産圏との均衡状態にあった。1980年、アメリカはソ連ではなく、共産主義の北ベトナムに敗北、イランでは油田がソ連の手に落ちつつあった。ソ連を封じるために、アメリカは毛沢東の中国と手を組みはじめた。2000年、ソ連は完全に崩壊した。中国は実質的には資本主義化し、NATOは旧共産圏の国々にも影響を及ぼしていた。世界は豊かで、最貧国の地域問題に注力すればよいものと思われていた。しかし、2001年9月11日、世界が覆される。これらのポイントは、歴史は20年というスパンでいかに変化するか、その時「よそく」されてないことが起こるか、ということである。
著者は本の冒頭で、21世紀はアメリカの世紀であると説く。アメリカが凋落しつつあると言われてしばらくだが、その力はいまだ若い青年のそれであり、青年特有の不安により、力に対する溺れがない。なぜアメリカが台頭したか?その大きな理由の一つは地政学的な理由である。アメリカは北米大陸の覇者であり、その場所の利点は、太平洋と大西洋の両方に出られることである。1980年代初めに、史上初めて太平洋貿易額が大西洋を上回った。その二つの海を支配し、海軍を整備して支配下におけるという点で、北米大陸の地理的な利点は大きい。アメリカが恐れるのは、海の支配をおびやかす存在、すなわち、ユーラシア大陸を統一するような力の出現である。そのため、アメリカの中東域や東欧での行動は、勝利ではなく分裂をうながすことにある。
アメリカはその土地、資本、労働力という経済生産の3要素を豊富に持ちさらに軍事力の増強により、史上どの国もなし得なかった全世界の海を支配するということを成し遂げている。宇宙に配備された衛星により、地球上の海は全て監視下に置かれ、あらゆる場所に出撃できる海軍を保持している。アメリカの地政学的な戦略目標は5つあるとされる。北米を陸軍により支配すること、西半球、アメリカ大陸にアメリカをおびやかす国の作らせない、アメリカへの海上接近路を完全に支配する、物理的安全と国際貿易体制の支配のため、全海洋を支配する、いかなる国にもアメリカのグローバルな海軍力に挑ませない、の5つである。これらを達成すること
念頭にあるとすれば、ユーラシアにおけるアメリカの介入、たとえばアフガンやイラク、アルカイダ掃討なども「解決」を目指しているわけではないことの説明がつく第3章では、人口構造の破綻、ライフスタイルの変化といった事象を、政治的な影響を加味して分析している。産業の高度化によって、子供を持つことがコスト高になり、また女性の社会進出によって結婚の経済的側面が薄まり、さらに平均寿命の伸びによって子供をたくさん生む理由がなくなり、結果としていびつな人口構造が生まれつつある。伝統的な性別が意味を持たなくなり、結婚が経済的側面よりも感情面に重点が置かれるようになったことが、同性愛を認める社会運動ともつながる。 こうした運動の中心になっているのはアメリカであり、国内外から批判も浴びて混乱を生じさせている。一方、コンピューターの発達は、アメリカで大きく前進したが、その背後にはヨーロッパの形而上学に対をなすプラグマティズムがアメリカにおいて考えられてきたからと考えられる。こうした文化の面でも、アメリカを避けて世界を考えることはできない。
アメリカを中心に、次の世界での火種になりうるのは、日本を含めた東アジア、旧ソ連圏、ヨーロッパ、トルコを中心としたイスラム圏である著者は主張する。日本については、中国と同様に、中東・アジア・オーストラリアといった地域から輸入し、アメリカやヨーロッパに輸出するという構造が、アメリカに生命線を握られているに等しいという点で潜在的な紛争問題であるとする。またヨーロッパについてについては、ロシアと大西洋・中央ヨーロッパの緩衝地帯であるポーランドが争点になると考えられている。
2020年というスケールでは、ロシアと中国がアメリカとの紛争になると予測されている。しかし、中国は内部が統一されておらず、帝国を作るには分裂する要素が大きく、アメリカを脅かす存在にはなりえないとされる。また、現在のロシアは危険にさらされている。資源に恵まれている一方で、主要な都市からNATO軍が駐在しているところまで非常に距離が近い。このことから、ロシアは旧ソ連圏の地域を復活させるべく行動すると考えられる。その後冷戦の再現が起こるが、小規模なままロシアの自壊によって幕をとじる。
この時期の中国とロシアの崩壊によって、日本、トルコ、そしてポーランドが力を伸ばすと予測している。これらの国が力をつけ、アメリカが不安を覚えるようになる。特にトルコと日本に対する締め付けを厳しくするのが2040年代と考えられ、アメリカが国内問題をかかえる前後とされる。特に軍事転用可能な技術の輸出を止め、また日本の製品の輸入を制限し始める。またアメリカや日本は宇宙開発を急速に進め、民間商業用に見せかけた軍事用の開発が進む。
2050年代に起こる戦争は日本−トルコ同盟のアメリカの宇宙戦艦に対する先制攻撃から始まるとされる。この戦争は結果的にはアメリカの勝利で終わり、日本やトルコは主に宇宙開発を制限される。ここで重要なのは、民間の被害が少ないことである。世界第二次大戦時は、民間人と軍人の差があいまいだったものがこの頃はその専門性からはっきりとその差が分かれると予測される。
2060年代にはアメリカは好景気と謳歌するとされるがそれが2080年代になると移民の問題とともにメキシコとの対立が表面化してくる。
これらの予測は、国家の地理的な条件を制限とし、国家の目的、すなわち安全保障や利益の拡大を達成するために起こりうる事象を予測している。これは国家が合理的に行動するという仮定になりたっている。このアプローチは経済学の合理的経済人に似ている。事前の予測は合理的であっても、様々なエラーにより細部に至る予測はまずあたることはない。しかし国家の目的や地理的条件といったも制限は100年単位で不変であり、その不変なものをもとに長期の予測を立てるアプローチに学ぶべき部分が多々ある。特に日本が置かれている状況を考えると、現在の安保法制の議論や、武力に関する憲法の議論なども違う側面が見えてくる。これはかならずしも武力を保持することを支持するものではないが、武力を保持することによって避けられるリスクと、本質的な意味での平和への道筋の相違点、および共有できる点を考えることで、予測と行動を考える必要がある。
ちょっと、日本のこと買いかぶりすぎじゃね?と思う面もありますが、地政学を元に論理的に予測するとこうなる、という考え方は興味深いです。
ご本人は、もともとは日米の対立(貿易摩擦など)のあたりがご専門だったみたいです。
最近は、ご本人もTwitterでアクティブなようです。
In “The Next 100 Years,” I forecast a period in which Russia would become more assertive, followed by a period of increased economic weakness and social disappointment. The fall of the Soviet Union failed to deliver what Russia has always longed to be: a modern European country. pic.twitter.com/NFmMapaPBt
— George Friedman (@George_Friedman) March 27, 2022
また、100年予測のアップデート版も出てるみたいですね。
時間を見つけて読んでみようと思います。
")
")