労働許可 (work permit)の更新
8月で労働許可 (work permit)が切れるのだが、更新するとも言ってないのにUDI(移民局)から更新の通知メールが来ていた。
メールによれば、F-codeというコードを使って、Fast trackという文字通り早い手続きで更新申請ができるらしい。
おそらく職種などによるのであろうが、素早くできるのはありがたい。
F-codeを使わない場合は一般の手続きになるそうなので、新規と同じような扱いになるのだろうか?
F-codeが有効になる場合の条件が決まっていて、
- 前年にノルウェーに居住・労働していた
- 現在の労働許可の期間のうち多くをノルウェーに居住していた
- 同じ職種についている。(雇用主が変わっても同じ職種である)
- 以前と同じか高い年収・賃金を得ている。
- 逮捕歴・犯罪歴がない
などです。4つ目地味に怖いな。給料が減るとFast trackではなくきっちり審査されるんでしょうか。
UDIにログインし、メールで送られてきたF-codeを入力した後、必要な情報を入力したら、
面接日程を予約します。私はベルゲンの外国人労働者サービスセンター(Service center for foreign workers in Bergen)で受けることになりました。
予約した日時に、以下の書類を持っていきます。
- サインしたカバーレター
- 居住者カード
- 有効なパスポート
- 雇用オファーフォーム
- 直近3回分の給与明細
カバーレターというのは、UDIのフォームで入力・申請した後に勝手に生成されてPDFをダウンロードできるようになるので、印刷してサインします。
雇用オファーフォームは、次に働くところ(継続して働く場合は現雇用先)から必要な情報を入力してもらってサインしてもらう必要があります。契約書から書ける可能性もありますが、結局サインが必要なので、私は入力してもらうようにお願いしました。
運良く一週間ほど後に予約が取れましたが、時期によってはもう少しとれないことも。
問題なければ面接日に書類を提出、写真を撮影して、10日ほどで新しい住民カードが届くはずです。
【R】RからStataのデータを書き出すときのエラー
Rでデータ分析してるのですが、時々「これStataの関数で走らせてみたい」とか「他の人はStataメインなのでデータ共有するのにstata形式で書きだしたい」というときがあります。
古いバージョン(Stata 12以前?)はforeignパッケージのwrite.dtaで書き出し、read.dtaで読み込みができたけど、13以降で少しフォーマットが変わったのかエラー吐くことも多いみたいです。
13以降の書き出しはhavenパッケージのwrite_dtaが良いようです。
haven::write_dta(df, "df.dta")
データの読み込みもreadstata13というパッケージもありますが、havenパッケージでよいのではないでしょうか。
# readstata13を使う場合 readstata13::readstata13("df.dta") # havenを使う場合 haven::read_dta("df.dta")
エラー
haven::write_dtaで以下のようなエラーが出ました。
Writing failure: A provided name contains an illegal character.
調べてみると、変数名(列名)がstataで受け付けるタイプではなかったことが原因のようです。
特殊記号をアンダーバーに変えたり、大文字を小文字に直したりする必要がありますが、これは以下の関数で一発解決。
df_new = janitor::clean_names(df) haven::write_dta(df_new, "df_new.dta")
dfのところは各自のデータフレームを入れてください。
【R】有限の台を持つポワソン分布っぽい分布を書く
ポワソン分布に基づいているけど、台(support)が無限ではなく任意の有限値で区切るような確率分布関数をR関数で書いて、
結局使わなかったけど、ここに供養しておこう。
普通のポワソン分布
普通のポワソン分布は台に非負の整数を取る確率関数である。
たとえばパラメーター(ラムダ)が2で、0から10までのポワソン分布の確率質量関数は
> dpois(0:10,2) [1] 1.353353e-01 2.706706e-01 2.706706e-01 1.804470e-01 9.022352e-02 3.608941e-02 [7] 1.202980e-02 3.437087e-03 8.592716e-04 1.909493e-04 3.818985e-05
となるが、理論上はポワソン分布の台は無限なので、10までの確率質量関数を合計しても1にはならない。
> sum(dpois(0:10,2)) [1] 0.9999917
有限の台を持つポワソン分布に基づいた分布
なんでこんな分布がほしかったかというと、有限離散のサンプルを取るときに、sample()関数だと一様分布に基づいたサンプルになってしまうが、いい感じのウェイトを付けたかったからである。
ようするに、任意の台の範囲で合計が1になればいいので
という感じで合計の確率質量で割って確率を定義するだけ。
dpois_bnd <- function(x,lam) {dpois(x,lam)/ppois(max(x),lam)}
これに基づいた疑似乱数生成を行うと
rpois_bnd <- function(lam,maxval){ if(is.na(lam)){ NA }else{ sample(0:maxval,1,replace = TRUE, prob = dpois_bnd(0:maxval,lam)) } # This function means: draw from 0 to 10 based on the distribution of Poisson(lambda) # The distribution is adjusted so that the sum of prob. is 1 even though truncatetd at 10 # sum(dpois(0:10,lam)/ppois(10,lam)) = 1 for any lambda # sum(dpois_bnd(0:10,lam)) }
まぁ結局使わなかったんですが…
上述のように、離散のサンプリングするときにウェイトをかけたいときに使えるかも、という程度です。

- 作者:岩沢 宏和
- 発売日: 2016/10/10
- メディア: 単行本
【計量経済学】資源・環境経済学における因果推定の最前線: JAEREの特集

刊行予定のJournal of the Association of Environmental Resource Economistsの特集で
"Causal Inference in Environmental and Resource Economics: Challenges, Developments, and Applications"というのが出る。
資源・環境経済学でよく用いられる因果推定手法についての研究や、その応用についての研究の特集だが、手法系の3本のサマリーだけざっと読んだのでメモ。
1. "What are the Benefits of High-frequency Data for Fixed Effects Panel Models?"
Ghanem & Smith
https://www.journals.uchicago.edu/doi/10.1086/710968
要約
データを集めるコストが低い時代になって、多くの高頻度データ(日毎、1時間毎など)が利用可能になっているが、分析のしやすさなどから低頻度にっ集計して使うケースがよく見られる。
特に固定効果モデルにおいて、高頻度データと集計された低頻度データでパラメータに一致性があるかどうかを計量経済学的に評価したのがこの研究である。
結論としては、データを集計する際には、高頻度のデータにおいてどういうデータ生成プロセスがあるかを考慮しないといけない、としている。
例えば、
- 効果に対する異質的な反応
- 高頻度と低頻度のデータの共変数に対する異なった反応
- 高頻度データにおける共変数に対する非線形的な反応
- 観察されない異質性のレベルの数が高頻度と低頻度で変わる
ことなどを考慮して、集計してよいかどうかを判断する必要がある。
メモ
非常に重要な観点で、固定効果ではないが高頻度データとその集計という意味では自分の研究にも関わる。
2. The Role of Parallel Trends in Event Study Settings: An Application to Environmental Economics
Marcus and Sant'Anna
https://www.journals.uchicago.edu/doi/10.1086/711509
要約
差分の差分法において、異なったタイミングの処置や政策施行が行われた場合(イベントスタディ)の平行トレンド仮定(Parallel Trend Assumption) について、どういった仮定を立てているかきちんと考慮すべきだとしている。また論文の中で提案されている推定法は、既存の手法よりも弱い平行トレンド仮定でも一致性を保つことができる。
メモ
それぞれ異なった平行トレンド仮定というのがどういうものか、もう少し時間を取って読みたい。
3. Measuring Heterogeneous Effects of Environmental Policies using Panel Data
Steigerwald, Vazquez-Bare, and Maier
https://www.journals.uchicago.edu/doi/10.1086/711420
要約
差分の差分法などで一般的に用いられる2変数固定効果(Two-way fixed effects)は、個人などの単位と、時間についての固定効果を含めるものだが、
この推定法は政策タイミングのばらつきや、効果の異質性がある場合には問題を生じさせるという指摘をおこなっている。
また、時間によって効果が異なる場合、たとえば政策施行直後としばらく経った後での効果などの場合は、サンプルピリオドによって推定値が変わることが指摘されている。つまり、サンプルピリオドによって、異なるパラメータが推定されていると理解されるべきである。
メモ
有効クラスター数とは?
クラスターの異質性を考慮して、実際のクラスター数より少ない有効クラスター数を用いて標準誤差を計算することによって
頑健性が担保されるという研究がある。
https://www.mitpressjournals.org/doi/pdf/10.1162/REST_a_00639

【R】固定効果モデルの推定がめっちゃ速いパッケージ { fixest }
以前から話題になっていたが、最近のアップデートで操作変数法にも対応したということで使ってみたら、めっちゃ早かったのでシェア。
Rで固定効果モデル(経済学でいう固定効果モデル)を推定する場合、方法はいろいろあるが、基本的なものはlm()にダミー変数をfactorで入れたり、
パネルデータ分析のパッケージであるplmパッケージのplm()関数を使うものがある。
estimatrパッケージでも固定効果を入れて推定することが可能である。
keita43a.hatenablog.com
ただ、問題はサンプルサイズが大きくなった場合と固定効果の変数の数が増えた場合に、推定に著しく時間がかかることである。
estimatrでも固定効果を3ついれたりすると、収束しなかったりすることがある。
そんな大きなデータセットにおける問題を解決すべく登場したのがlfeパッケージのfelm()関数なのであった。
しかし、それを速さで超えてくるパッケージがfixestなのである。
まずリンク先の最初の図を見てほしい。ベンチマークで速さを比較したものであるが、lfeだけでなくjuliaのFixedEffectModelやStataのreghdfeにも勝っている。*1
fixestの特徴
fixestパッケージの特徴としては大きく2点あると思う。
- めっちゃ速い。
- OLS以外にGLMの関数も用意されている。
めっちゃ速い
本家のグラフで一目瞭然だが、自分でも比較してみた。
以下のサンプルデータ(n = 1000000, 固定効果カテゴリ4つ)で推定した結果を見ていただこう。
# パッケージ library(tidyverse) library(lfe) library(fixest) set.seed(3) # データセットアップ n <- 10^6 data1 <- tibble::tibble(x1 = rnorm(n), x2 = rnorm(n), x3 = rnorm(n), x4 = rnorm(n), id = factor(sample(20,n,replace=TRUE)), firm = factor(sample(13,n,replace=TRUE)), year = factor(sample(2010:2020,n,replace=TRUE)), group = factor(sample(15,n,replace=TRUE)) ) ## 固定効果 id.eff <- rnorm(nlevels(data1$id)) firm.eff <- rnorm(nlevels(data1$firm)) year.eff <- rnorm(nlevels(data1$year)) group.eff <- rnorm(nlevels(data1$group)) ## 従属変数 data1 <- data1 %>% mutate(y = 1*x1 + 0.5*x2 + 2*x3 + 3*x4 + id.eff[id] + firm.eff[firm] + year.eff[year] + group.eff[group] + rnorm(n))
## 推定と比較 mbm <- microbenchmark::microbenchmark( felm = felm(y ~ x1 + x2 + x3 + x4 | id + firm + year + group, data1), fixest = feols(y ~ x1 + x2 + x3 + x4 | id + firm + year + group, data1) ) autoplot(mbm)
結果の比較がこちらである。

データが簡素なのでどちらも速いが、それでもfixestが速い。
GLMの関数もある
OLSだけではなく一般化線形モデル(GLM)のポワソン回帰やロジスティック回帰も使える。
| 線形回帰(OLS) | feols() |
| ポワソン回帰 | feglm(, family = "poisson") |
| 負の二項回帰 | fenegbin() |
| ロジスティック回帰 | feglm(, family = logit") |
使い方
基本的な使い方は、丁寧なIntroductionが英語で用意されているのでここでは簡単な紹介に留める。
1. 基本の関数
基本的な式の書き方は | で変数と固定効果を分ける書き方である。
model1 = feols(y ~ x1 + x2 + x3 + x4 | id + firm + year + group, data1)
GLMはデフォルトのファミリーがポワソンになっているので、ポワソン回帰を行う場合は指定は不要である。
data(trade) # sample data model2 <- feglm(Euros ~ log(dist_km)|Origin+Destination+Product+Year, trade)
2. クラスター標準誤差
クラスター標準誤差の計算もしっかりオプションが用意されている。
例えば、固定効果の最初の2つのカテゴリについてクラスター標準誤差を計算したい場合はsummary関数の中で se = "twoway"とする。
summary(model2, se = "twoway")
このseの指定は"cluster"で1つのカテゴリ、"threeway"で3つ、"fourway"で4つの指定が可能である。
また、特定のカテゴリでクラスター標準誤差を計算したい場合はclusterオプションを使う
summary(model2, cluster = "Product") summary(model2, cluster = ~Product) #同じ結果
さらにロバスト標準誤差(HC1)はse = "hetero"で計算できるので、固定効果を使わないモデルのOLSとしても使うことができる。
3. 固定効果の推定値
summary関数では固定効果を除いた変数の係数推定値が表示されるが、固定効果自体に興味がある場合はfixef()関数で取り出せる。
fixed_effect <- fixef(model1) summary(fixed_effect) fixed_effect$year # 特定のカテゴリの取り出し
またplot関数で、もっとも差の大きな値の比較が簡単に可能になっている。(すべての固定効果推定値が表示されてないことに留意)
plot(fixed_effect)
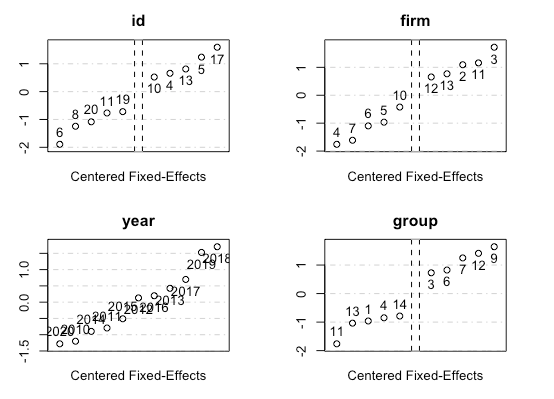
この他にも、カテゴリ同士の結合(e.g. 月-年効果)、グループごとに変わる係数の推定(e.g. 男女で異なるβ) 、パネルデータ作成による簡単なラグ変数の作成などの機能も盛り込まれている。
テーブル(表)への出力
論文やレポート作成において、推定した結果をエクスポートして活用するのは、手間が省ける以上に再現可能性やミス回避のために重要だ。
以前紹介の記事を書いたmodelsummaryだが、公式では関数を書くことで、固定効果を表示するテーブルを出力することが可能となっている。
https://vincentarelbundock.github.io/modelsummary/articles/newmodels.html#fixed-effects-regression-1vincentarelbundock.github.io
しかし、fixestはパッケージの中にetableというテーブルへの出力関数が含まれている!
いたれりつくせりだな!!!
model2 <- feglm(Euros ~ log(dist_km)|Origin+Destination+Product+Year, trade) summary(model2)
> etable(model1_noFE, model1, cluster = "firm") model1_noFE model1 (Intercept) -0.4849 (0.3075) x1 1.006*** (0.001831) 1.002*** (0.000965) x2 0.5029*** (0.002008) 0.5017*** (0.001129) x3 1.998*** (0.001486) 2*** (0.00103) x4 2.997*** (0.002595) 3*** (0.000737) Fixed-Effects: -------------------- -------------------- id No Yes firm No Yes year No Yes group No Yes ___________________ ____________________ ____________________ Observations 1,000,000 1,000,000 S.E. type: Clustered by: firm by: firm R2 0.74832 0.94743 Within R2 -- 0.93442
etable(model1_noFE, model1, cluster = "firm", tex = TRUE)

もちろんカスタマイズが可能になっている。
くわしい設定方法としても、Vignetteが準備されている。
Exporting estimation tables

*1:2020年2月時点のデータであることに留意。他のパッケージにアップデートが入った可能性はある。
【R】 broomパッケージ入門: Rのモデル出力を整然化(tidy)する
入門記事というより、俺が入門(おさらい)した内容をまとめています。
分析結果を自動的に出力するために modelsummary::msummary() をもう少し深く勉強しているうちに、broomパッケージの内容をもうちょっときちんと理解せんといかんな、と思っておさらいすることにしました。
broom パッケージとは?
Rにおける様々な統計分析モデルで分析した結果って、各々の関数のオブジェクトとして出力されるのですが、
それを一律にtidyなオブジェクトとして出力しよう、というアイデアのパッケージです。
Rで行った分析をそのまま見るだけなら、コンソールに出力して見るだけでいいのですが、
レポートに含めたり、また分析された結果を加工したり別のモデルに利用する時に、出力されたデータがtidyでないと煩雑なプロセスを踏んで加工する必要が出てきます。そういった手間を省き、整然な出力を行うことができるのがbroomパッケージです。
整然データ (tidy data)とは?
R界の神、Hadley Wickam氏によって提案された一律の構造に則ったデータ形式のことです。
基本的に各行(→)が一つ一つの観察値であり、各列(↓)が一つの変数である形を持っています。
Rのオブジェクトは主にリストの形で、いろいろな形のオブジェクトを一つにまとめたような形になっていますが、関数によって形式や含む要素がバラバラのため、扱いにくいため、これをtidy dataのルールに則って出力するパッケージがbroomということになります。
broomの3つの関数
broomには3つの異なった整然化を行うメソッドがあります。
1. tidy : 統計モデルの結果を整然データとして出力する。
2. augment : 統計モデルに入力する元データに、出力結果を付加する。(例:予測値など)
3. glance : 統計モデルの結果に関する一行のサマリーを出力する。
一つ一つ見ていきます。
1. tidy: 係数などの整然化
例としてmtcarsのデータを使って線形回帰を行います。
出力された結果の
library(broom) lmfit <- lm(mpg ~ wt, mtcars)
出力されたオブジェクトはlmというオブジェクトです。
> class(lmfit) [1] "lm"
一般的には summary()関数を使って結果をコンソールに出力します。
> summary(lmfit) Call: lm(formula = mpg ~ wt, data = mtcars) Residuals: Min 1Q Median 3Q Max -4.5432 -2.3647 -0.1252 1.4096 6.8727 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 37.2851 1.8776 19.858 < 2e-16 *** wt -5.3445 0.5591 -9.559 1.29e-10 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 3.046 on 30 degrees of freedom Multiple R-squared: 0.7528, Adjusted R-squared: 0.7446 F-statistic: 91.38 on 1 and 30 DF, p-value: 1.294e-10
もちろんコンソールで見る限りは見やすい結果なのですが、この結果をさらに加工したり、係数だけ取り出して図を作ったりするのに手間がかかります。
しかし、tidy()を使えば一発で整然化されたデータフレームで出力されます。
> tidy(lmfit) # A tibble: 2 x 5 term estimate std.error statistic p.value <chr> <dbl> <dbl> <dbl> <dbl> 1 (Intercept) 37.3 1.88 19.9 8.24e-19 2 wt -5.34 0.559 -9.56 1.29e-10
上では、各行が各係数の結果、各列は係数についての推定値、標準誤差、t-統計量、p値がそれぞれ入っています。
これは各行が観察値、各列が変数、という整然データの概念に一致しています。
2. augment: 予測値などの整然化
lmによって推定した結果を用いて予測値を追加したいとします。元データの各行(すなわち各観察値)に対して予測値を追加したい場合は以下のコマンドで簡単に追加できます。
> augment(lmfit) # A tibble: 32 x 10 .rownames mpg wt .fitted .se.fit .resid .hat .sigma .cooksd .std.resid <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> 1 Mazda RX4 21 2.62 23.3 0.634 -2.28 0.0433 3.07 0.0133 -0.766 2 Mazda RX4 Wag 21 2.88 21.9 0.571 -0.920 0.0352 3.09 0.00172 -0.307 3 Datsun 710 22.8 2.32 24.9 0.736 -2.09 0.0584 3.07 0.0154 -0.706 4 Hornet 4 Drive 21.4 3.22 20.1 0.538 1.30 0.0313 3.09 0.00302 0.433 5 Hornet Sportabout 18.7 3.44 18.9 0.553 -0.200 0.0329 3.10 0.0000760 -0.0668 6 Valiant 18.1 3.46 18.8 0.555 -0.693 0.0332 3.10 0.000921 -0.231 7 Duster 360 14.3 3.57 18.2 0.573 -3.91 0.0354 3.01 0.0313 -1.31 8 Merc 240D 24.4 3.19 20.2 0.539 4.16 0.0313 3.00 0.0311 1.39 9 Merc 230 22.8 3.15 20.5 0.540 2.35 0.0314 3.07 0.00996 0.784 10 Merc 280 19.2 3.44 18.9 0.553 0.300 0.0329 3.10 0.000171 0.100 # … with 22 more rows
推定に使用したmpgとwtという変数に加えて、以下の変数が追加されている。追加された変数は . (ドット)から始まる。
- 予測値(.fitted),
- 予測値の標準誤差(.se.fit),
- 残差 (.resid),
- 標準化残渣 (.std.resid),
- 射影行列の対角(.hat)
- 各行が除かれて推定された場合の残差標準誤差の推定値 (.sigma)
- 各行が除かれて推定された場合の予測値の変化(クック距離) (.cooksd)
3. glance: モデル適合度などの整然化
glance()関数を使うと、モデルの出力のうち、モデル適合値など一つの値で代表される統計量を一行のデータフレームで示す。
> glance(lmfit) # A tibble: 1 x 11 r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC deviance df.residual <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <int> 1 0.753 0.745 3.05 91.4 1.29e-10 2 -80.0 166. 170. 278. 30
broomの使用例
etimatrの結果
Rに最初から入っているパッケージだけではなく、様々なパッケージが利用できる。
estimatrの結果もtidyにできるが、lm()とは少し出力される変数が異なる。
> library(estimatr)
> # mtcarsを使った推定
> lmrob <- lm_robust(mpg ~ wt, mtcars)
> tidy(lmrob)
term estimate std.error statistic p.value conf.low conf.high df outcome
1 (Intercept) 37.285126 2.2689318 16.43290 1.514499e-16 32.651349 41.918903 30 mpg
2 wt -5.344472 0.6832764 -7.82183 9.959194e-09 -6.739908 -3.949035 30 mpg
dplyrのパイプの中で使う。
これは効果検証入門の2.2.7からの抜粋ですが、
cor_visit_treatment <- lm( data = biased_data, formula = treatment ~ visit + channel + recency + history) %>% tidy()
のように、lmで推定したものをパイプ(%>%)でtidy関数に受け渡してしまうと、そのまま整然化されたデータフレームが取得できます。
まとめて回帰分析を実行する。
これも効果検証入門から抜粋です。(2.2.3)
以下のコードは事前にmodelsというデータフレームに複数の推定式を入れています。
二行目で、各モデル(formula)に対して、lmという関数をbiased_dataというデータを使って実行するという繰り返し(map)を行い、
3行目で、得られた各結果(model)に対して、tidyという関数をそれぞれ実行するという命令になっています。
df_models <- models %>% mutate(model = map(.x = formula, .f = lm, data = biased_data)) %>% mutate(lm_result = map(.x = model, .f = tidy))
エレガントですね。
詳しいコードについては効果検証入門を参照してください。
コードはこちらにあります。
使えるモデル・パッケージ
broomを使えるモデルやパッケージはどんどん増えていて、全てを挙げるのは難しいですが、計量経済学関連だと以下のようなパッケージが使えるのがありがたいです。(ご存じだと思いますがパッケージ::関数という表記です。)
- estimatr: ロバスト標準誤差、操作変数、固定効果など基本的な計量経済学の推定ができる。estimatr::lm_robust, iv_robustなど。
- lfe : 複数の固定効果モデルを含めて推定できるlfe::felmなど。
- fixest : 複数の固定効果モデルを速く推定するfixest::feolsなど
- mfx : ロジット・プロビットなどの限界効果を計算するmfx::mfx, logitmfx, negbinmfx, poissonmfx, probitmfxなど
- spatialreg : 空間回帰分析のできるspatialreg::sarlmなど
- gmm : GMM(一般化モーメント法)の推定ができるgmm::gmmなど。
参考文献
効果検証入門

tidyverse ブログ
https://www.tidyverse.org/blog/2020/07/broom-0-7-0/#new-tidier-methods
Introduction to broom
https://cran.r-project.org/web/packages/broom/vignettes/broom.html
【ノルウェー】スタヴァンゲル旅行記3:世界最多段の木造階段フローリ
仕事が忙しくだいぶ間が空いてしまったが、スタヴァンゲル旅行で書き残しておきたいものが残っていた。

シェラグに行くことを断念した私達は、代わりに何するか調べいていたら、このフローリ(Flørli)のトレイルに行き着いた。
世界最長の木造階段という触れ込みで、4444段の木造階段が水力発電所として使われていたパイプラインに沿っている。*1
しかも、船でしか行けないというのもミステリアスな感じがして面白い。グーグルマップで行き先指定するとエラーが出てルートが表示できない。*2
行き方
フローリへのアクセスは基本的にはフェリーのみだ。
スタヴァンゲル市街から行く場合はスタヴァンゲルの港から公共交通のKolumbus社の船が出ているが、昼の1時から一本しかなかった。トレイルをぐるっと回って帰ってきてまた船に乗る時間を考えると日帰りは難しい。宿泊施設もあるし、複数のトレイルやカヌーなども楽しめるそうなので、時間があるなら泊まるのも楽しそうだ。カップル用の特別な部屋(小屋)プランもあるらしい。
そこでもう一つ、夏の間だけはThe Fjord社が運行するクルーズ観光船がある。(スケジュール)
これなら朝9:30発に乗って10:50にフローリに到着し、ハイキングを楽しんで少しゆっくりしたあと18:40発の船で帰ることができる。
車でLauvvikというリーセフィヨルドに近い港に行き、そこから観光船に乗ることができる。車でフローリに乗り入れすることは不可能ではないが、港近辺の狭いスペースに駐車するしかないし、基本的に推奨されていないので、Lauvvik港の無料駐車場に停めてから乗船した。
フィヨルド観光船なので、フローリに向かう船からの景色も絶景だ。大きな滝や、下からプレーケストーレンを見上げることができる。


トレイル
トレイル情報はOutttで確認できる。
所要時間4~5.5時間とあるが、実際に5時間ちょっとだったように思う。
船着き場の近くの建物の横からすぐに階段が伸びていて、4444段が始まる。
その後は上までずっと登っていくのみ。

下の写真の奥に見えるぐっと登っているところは、本当に急で、階段もそこまで板2枚分あったものが、1枚分になる。

このあたりは左右は森になっているのだが、虫が多かったので虫除け対策をしていくことをおすすめする。
私はあまり気にしてなかったのだが、ヌカカという虫に20箇所ぐらい咬まれて、翌日にすごいかゆみが襲ってきた。
ノルウェーの病院に相談すると、ステロイド系の塗布薬を処方されてなんとかなったのだが、実際にこれで悩まされてる人は日本にもいるらしいのでお気をつけて。
500段ごとに、プレートに段数が示されている。
4000段の少し手前ぐらいまで来ると、平らになり、風景が開けてくる。
少し登れば4444段達成。しかし4000段前後から階段か?みたいな感じの板の上を歩くことになるし、厳密には4444より少し多い。

少し登れば貯水池が見える。ここがこのトレイルで一番高いところだ。

その後はずっと下りだが、なかなかの岩の多い悪路を降りていくことになるので注意が必要になる。
階段自体はスニーカーでも登れるが、降りることを考えるときちんとした登山靴で臨むほうが良い。
このトレイルのレベルが「Demanding(難しい・厳しい)」にカテゴライズされているのは、階段自体が急で危ないというのもあるが、
この下りの道が歩きづらいという点もあるように思う。
